参考《JavaNIO》
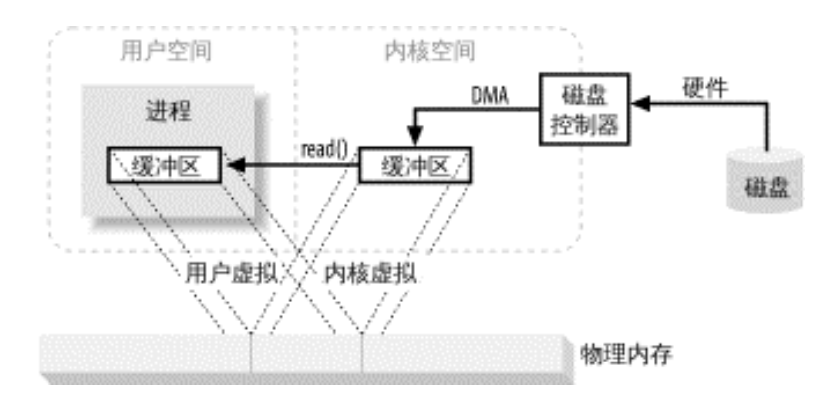
为什么需要缓存区
1,硬件通常不支持直接访问用户空间(java进程处于用户空间)
2,磁盘操作的是固定大小的数据块,而用户进程请求可能是任意大小的数据块,需要内核进行分解再组合
虚拟内存的好处
1,一个以上的虚拟地址指向同一个物理内存
2,虚拟内存可以大于硬件内存
可以把用户空间的与内核空间的虚拟内存映射到同一块物理内存省去内核空间与用户空间的来回拷贝
NIO与BIO的区别
NIO面向缓冲区,BIO面向流,NIO每次处理必须判断缓冲区数据准备完毕才处理
NIO适合多连接,小数据量
BIO适合少连接,大数据量
Buffer(各种Buffer的父类都是抽象类Buffer)
属性位置:0<=mark<=position<=limit<=capacity
新建Buffer默认mark,position为0,limit,capacity相等为指定值
默认所有Buffer都是可读可写的,可以使用FloatBuffer onlyBuffer = buffer.asReadOnlyBuffer();显示声明只读
get与put方法都有绝对与相对之分,而且支持批量操作(数组/对应Buffer)
一般都是put/get声明类型数据,不过ByteBuffer支持几乎所有类型(注意获取时需要按设置的顺序否则乱码,且若剩余不够会抛出异常)
flip方法
java">public final Buffer flip() {
limit = position; //防止读出界
position = 0; //归零位置
mark = -1; //清除标记
return this;
}
rewind方法
java">public final Buffer rewind() {// 注意没有设置读取上界
position = 0;
mark = -1;
return this;
}
其他方法
remaining:获取剩余值(limit - position) clear:恢复指针到原来的状态
compact:对内容压缩,把pos~lim的内容移动到最左边,pos设置到应该写入的位置,limit恢复最大,清除标记
mark:设置当前位置为标记 reset:恢复之前设置的标记(必须有,注意有些函数会清除标记)
compareTo:会先比较每一个get的值,有一个不同就返回,再比较谁有剩余
arrayOffset:获取底层数组的偏移(主要针对wrap产生的缓冲区)
duplicate:复制缓冲区,与原来的同用,同一内存,其他属性复制(例如直接缓冲区,只读等)
slice:与duplicate相比会把剩余没使用的空间(position~limit)切割出去(类似compact),其他类似,会出现arrayOffset不为0的情况
创建Buffer(都是使用静态方法)
allocateDirect(),使用unsafe.allocateMemory(size);直接申请内存(注意只有ByteBuffer支持申请直接内存)
allocate(),super(-1, 0, lim, cap, new byte[cap], 0);通过数组生成
wrap(),包装数组生成,有指定偏移与数量的重载
字节排序
分为小端字节序与大端字节序,Java默认字节排序为大端字节序
可以使用duplicate.order(ByteOrder.nativeOrder())指定排序
ByteBuffer转为其他Buffer是公用内存的
java">ByteBuffer buffer = ByteBuffer.allocate(12);
CharBuffer buffer1 = buffer.asCharBuffer();// 底层是公用的
buffer.put((byte) 0);// 用于补充高位
buffer.put((byte) 'h');
buffer.put((byte) 0);
buffer.put((byte) 'i');
buffer.put((byte) 0);
buffer.put((byte) '!');
System.out.println(buffer1);// 输出 hi!
通道
InterruptibleChannel接口,指定该通道是可中断的
FileChannel
一般通过输入输出流获取FileChannel
也可以使用FileChannel.open(Path path, OpenOption… options)创建文件通道
一般通道是双向的不过,通过输入/输出流获取的通道是单向的
线程安全,不过部分方法线程不安全,例如查看文件的大小
FileChannel.position(1);//设置指针位置,不能为负值,若超出文件尾,不会改变文件大小,若这时读取会返回文件尾标识,若写入会产生文件空洞,position是底层文件描述提供的,若更新,多个共享对象都会看到(实际测试多个指向同一文件的通道并不共享position)
FileChannel.truncate(1024);//会把指定长度后面的内容删除,并把数据刷新到硬盘,若指定size大于文件不会修改
FileChannel.force(true);//强制将文件内容写入硬盘(布尔值代表是否同时写入元数据)
文件锁
有共享锁与独占锁,但是有些操作系统没有共享锁,申请共享锁会升级为独占锁
文件锁是文件关联,操作系统管理的,例如一个Java程序多线程获取文件独占锁都会成功,但是多个程序不行(面向进程)
FileChannel.lock(<开始>,<结束>,<是否共享锁>);//阻塞锁定指定区域,无参的相当于lock(0L, Long.MAX_VALUE, false);
FileChannel.tryLock();//非阻塞版本 获取失败直接返回null FileLock.release();//释放文件锁
文件内存映射
FileChannel.map(FileChannel.MapMode.READ_WRITE, 0, write1.size());(实例方法),指定映射模式(模式需要与通道模式匹配)与范围
FileChannel.MapMode.PRIVATE模式是写时拷贝,若发生写会拷贝到内存一份,只对当前映射可见
注意 第三个参数是size,若超出文件大小,会增加文件以适应(若只读模式,无法修改会直接报错)
内存映射一旦建立一直有效(没有关闭方法),直到它被垃圾搜集,即使关闭对应的FileChannel也有效
MappedByteBuffer.load();//提前加载文件到内存(就算提前加载也可能被替换出,推荐使用默认,使用时才加载) MappedByteBuffer.isLoaded()判断是否完全常驻内存,只操作部分不会完全常驻内存
ChannelToChannel
FileChannel.transferTo(0,read.size(),write)与FileChannel.transferFrom(read,0,read.size())用于管道传递文件,要求调用一方必须是FileChannel,另一方只要实现对应接口就行
可以使用Channels工具类方法在流与通道直接转换

Channel.close()
就算非阻塞模式,调用依旧可能阻塞(是否阻塞取决于操作系统与文件系统),在一个通道多次调用close()方法没有坏处,若第一个阻塞其他都会阻塞,若已经关闭会直接返回
java">public final void close() throws IOException {
synchronized (closeLock) {
if (!open)
return;
open = false;
implCloseChannel();
}
}
scatter/gatter操作(发散/汇聚映射)
write(ByteBuffer[] srcs, int offset, int length);//允许这样批量操作的 若为write(聚集) read(发散)
Socket通道类
所有的Socket通道类(DatagramChannel,SocketChannel,ServerSocketChannel)创建时都会创建一个对应类型的Socket对象(Socket,ServerSocket,DatagramSocket)对应的Socket对象getChannl()会返回其对应的通道,但是普通Socket对象getChannl()将为空
NIO是对BIO的优化底层还是Socket
非阻塞模式会立马返回
java">channel.configureBlocking(false);
SocketChannel accept = channel.accept();//非阻塞模式会立马返回 没有连接返回null
System.out.println(accept);// 打印null
java">channel.configureBlocking(false);
// 非阻塞的SocketChannel会立即返回通过返回值判断是否连接成功 connect没有可以指定超时时间的
boolean connect = channel.connect(new InetSocketAddress("127.0.0.1",2233));
其他方法
connect()与finishConnect()互相同步,若有一个在进行,任何读写都会被阻塞(即使在非阻塞情况下)
DatagramSocket使用
java">DatagramSocket datagramSocket=new DatagramSocket();
byte[] bytes = "HelloWorld".getBytes();//发送消息 必须指定发送地址 自己不需要绑定端口
DatagramPacket packet = new DatagramPacket(bytes, bytes.length,new InetSocketAddress("127.0.0.1",8888));
datagramSocket.send(packet);
java">DatagramSocket datagramSocket = new DatagramSocket(8888);// 监听端口接收信息
DatagramPacket packet = new DatagramPacket(new byte[1024],1024);
datagramSocket.receive(packet);//阻塞接收
Pipe使用
java">Pipe pipe = Pipe.open();// 获取管道
Pipe.SinkChannel sink = pipe.sink();//获取发送方 默认直接发送不阻塞(没有消费者直接丢弃)
Pipe.SourceChannel source = pipe.source();// 获取接收方 默认阻塞获取
Selector
Selector.open();//获取对象 Selector.close();//关闭对象 Selector.isOpen();//判断选择器是否关闭防止异常
SelectionKey selectionKey = channel1.register(selector, SelectionKey.OP_ACCEPT);//注册后返回SelectionKey可以获取注册的各种信息 selectionKey.cancel();//取消连接,会在下一次select时删除对应信息
Selector.wakeup();//停止阻塞选择 selector.select();//阻塞选择 selector.select(2233);//指定时间阻塞选择 selector.selectNow();//完全非阻塞选择
携带附加对象
java">// 构造时附加对象 注意附加对象要及时清除否则会造成内存泄漏
SelectionKey selectionKey = channel1.register(selector, SelectionKey.OP_ACCEPT,"");
selectionKey.attach("");// 后来附加对象 与上面是等价的
System.out.println(selectionKey.attachment());// 获取附加对象
使用例子
java">ServerSocketChannel channel = ServerSocketChannel.open();
channel.bind(new InetSocketAddress(2233));
channel.configureBlocking(false);
Selector selector = Selector.open();
// 注册感兴趣的操作
channel.register(selector, SelectionKey.OP_ACCEPT);
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true){
if(selector.selectNow()>0){// 有事件产生
Set<SelectionKey> keys = selector.selectedKeys();// 选择
// 这样遍历 底层 依旧使用 keys.iterator(); 推荐直接使用迭代器
for (SelectionKey key:keys){
if(key.isAcceptable()){
ServerSocketChannel channel1 = (ServerSocketChannel) key.channel();
SocketChannel accept = channel1.accept();
accept.configureBlocking(false);
accept.register(selector,SelectionKey.OP_WRITE);//注册新的
}else if(key.isWritable()){
SocketChannel channel1 = (SocketChannel) key.channel();
buffer.clear();
buffer.put("HelloWorld".getBytes());
buffer.flip();
channel1.write(buffer);
// 关闭连接 退出注册
channel1.close();
//key.cancel();// 关闭通道会自动在下一次select取消注册键
}
}// 清理keys
keys.clear();
}
}
正则表达式匹配引擎
确定有限自动机 非确定有限自动机
Pattern.compile的flags参数
Pattern.CASE_INSENSITIVE//不区分大小写匹配
Pattern.COMMENTS//忽略空白行与#整行注释
Pattern.DOTALL// 指定 . 可以匹配任意字符 默认无法匹配行终止符
Matcher使用
Matcher matcher = compile.matcher(“sdf11s6dsdfsdfgdsfgdfgdfhgfh”);//获取匹配情况
matcher.matches();//是否整个文本匹配正则
java">while (matcher.find()){//是否有 查找指向会后移 用于getAll操作
System.out.println(matcher.group());//获取新的底层调用group(0)
// 获取当前匹配的开始与结束 都可以使用数字指定分组 每个匹配都有分组
System.out.println(matcher.start()+":"+matcher.end());//不带参数的也会跟随find()指针
}
matcher.find(11);//从指定位置开始是否有匹配的
matcher.replaceAll(“LLL”);//匹配的全部替换 matcher.replaceFirst(“LLLLL”);//只替换第一个(字符串可以使用$num引用分组)
matcher.reset();//恢复
matcher.lookingAt();//判断是否开头匹配,不要求整个匹配
分组相关的(正则使用()表示分组)
matcher.groupCount();//获取分组数
matcher.group(1);//第一个分组,若指定为0是获取整个表达式匹配内容
matcher.start(1);//获取指定分组开始位置 matcher.end(1);//获取指定分组结束位置
可以使用 \\num 引用前面的分组 例如 (\\d)-\\1 表示 n-n 前面与后面必须一致
嵌套组,下标规则
有同级的先左后右,从一个开始,会把它先计算完,先外后内
appendReplacement与appendTail使用
java">Pattern compile = Pattern.compile("([Tt])hanks");
Matcher matcher = compile.matcher("Thanks AAAA thanks very math");
StringBuffer builder=new StringBuffer();
while (matcher.find()){
if(matcher.group(1).equals("T")){//分组是对每个匹配项的 若匹配 正则有分组 一定能获取分组
//将匹配内容替换然后把匹配之前的添加进StringBuffer 注意 目标字符串 可以使用 $num 引用指定分组
matcher.appendReplacement(builder,"$1-FIRST");
System.out.println(builder);//FIRST
}else {
matcher.appendReplacement(builder,"SECOND");
System.out.println(builder);//FIRST AAAA SECOND
}
}
matcher.appendTail(builder);// 用于附加匹配尾部信息(直接附加find()指针后面内容) appendReplacement只能添加之前的
System.out.println(builder);//FIRST AAAA SECOND very math
字符编码
java">String str="你好!世界";
byte[] bytes = str.getBytes(StandardCharsets.UTF_16);
// 解码时 必须与编码获取bytes的编码一致才不会乱码 不过注意 ISO_8859_1不支持中文
System.out.println(new String(bytes,StandardCharsets.UTF_16));
Charset charset=StandardCharsets.UTF_8;
// 编码
ByteBuffer hello = charset.encode("Hello");
// 解码
System.out.println(charset.decode(hello));
// 获取专门的编解码器 都不是线程安全的
CharsetDecoder decoder = charset.newDecoder();
CharsetEncoder encoder = charset.newEncoder();



